Robustná stratégia monitorovania a upozorňovania je základným kameňom úspešného pracovného postupu DevOps.
Nezabezpečuje len spoľahlivosť a výkonnosť systému, ale aj umožňuje tímom proaktívne riešiť problémy predtým, než ovplyvnia koncových používateľov. Úspešná stratégia monitorovania a upozorňovania kombinuje vhodné nástroje, metriky, procesy a automatizáciu, súlad s cieľom DevOpsu rýchlo nasadzovať softvér vysokej kvality. Ale kde začneme?
Nezabezpečuje len spoľahlivosť a výkonnosť systému, ale aj umožňuje tímom proaktívne riešiť problémy predtým, než ovplyvnia koncových používateľov. Úspešná stratégia monitorovania a upozorňovania kombinuje vhodné nástroje, metriky, procesy a automatizáciu, súlad s cieľom DevOpsu rýchlo nasadzovať softvér vysokej kvality. Ale kde začneme?
Definujte dosiahnuteľné ciele a metriky
Existuje množstvo nástrojov, ktoré pomáhajú pri zbieraní zdrojov, ktoré chceme sledovať. Avšak,
bez správnej konfigurácie, pokus o monitorovanie všetkého môže viesť k nadbytku neefektívnych metrík. Začnime s najbežnejšími konfiguráciami a preskúmajme nástroje, ktoré sú pre tieto úlohy najvhodnejšie:
bez správnej konfigurácie, pokus o monitorovanie všetkého môže viesť k nadbytku neefektívnych metrík. Začnime s najbežnejšími konfiguráciami a preskúmajme nástroje, ktoré sú pre tieto úlohy najvhodnejšie:
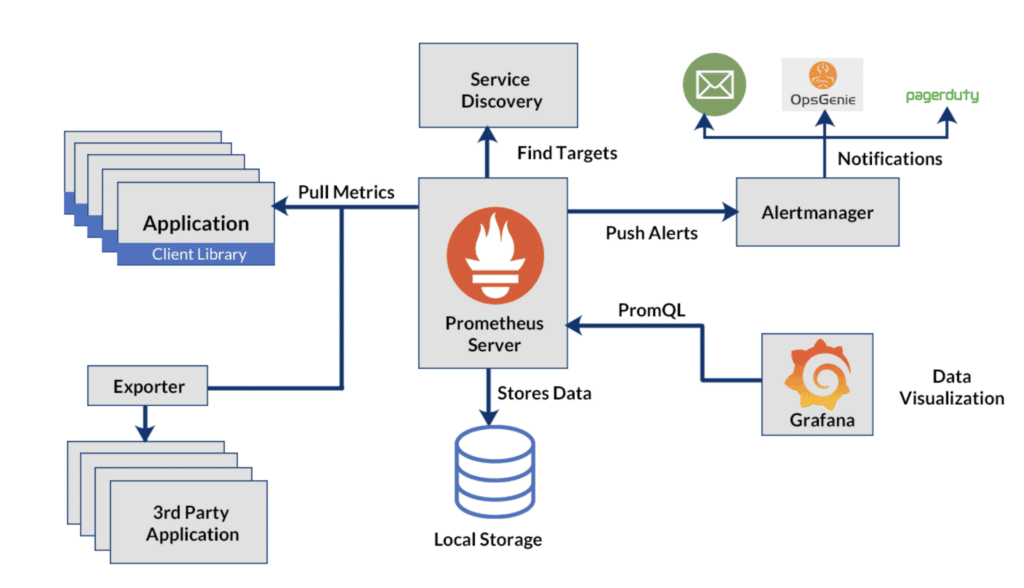
- Pre získanie logov , potrebujeme riešenie, ktoré dokáže sledovať miesto určenia logov a preposlať ich do centralizovaného úložiska. Loki spolu s Promtailom slúži na tento účel efektívne. Loki je navrhnutý pre horizontálnu škálovateľnosť , nákladovú efektívnosť a jednoduchú inštaláciu, čo ho robí ideálnou voľbou pre agregáciu a dotazovanie logov z rôznych zdrojov. Na druhej strane, Promtail je agent ,ktorý preposiela obsah miestnych logov do inštancie Loki, čím uľahčuje proces zberu logov.
- Pre metriky kontajnerov, ako sú celkové reštarty, využitie CPU a pamäte a ďalšie,
Prometheus je riešením. Je mimoriadne silný pri zbieraní a ukladaní
časových radových dát. Pri práci s Docker kontajnermi môže Prometheus zbierať
metriky priamo z Docker démona. Okrem toho, v prostredí Kubernetes
kube-state-metrics môže byť použitý vedľa Prometheusa. Kube-state-metrics
počúvajú na API serveri Kubernetes a generuje metriky o stave
objektov (ako sú nasadenia, uzly a pod-y), ktoré môžu byť potom zbierané
pomocou Prometheusu pre komplexné monitorovanie.
- Čo sa týka podkladovej infraštruktúry, metriky súvisiace s fyzickými alebo virtuálnymi
strojmi, ako je využitie CPU, pamäť, disk a sietí, sú kľúčové. Tu prichádza
do hry Node Exporter . Node Exporter je Prometheus exportér
ktorý zbiera hardvérové a OS metriky, ktoré sú vystavené *NIX jadrami, umožňujúce podrobné
monitorovanie systémových zdrojov a výkonu. Tento nástroj je nevyhnutný pre
získanie prehľadu o prevádzkovej integrite infraštruktúry podporujúcej vaše
aplikácie.
Vizuálny prieskum údajov
Keďže sme zhromaždili všetky naše zdroje a zozbierali metriky, môžeme sa venovať
fáze vizualizácie a analýzy, kde nástroje ako Grafana zohrávajú kľúčovú úlohu.
fáze vizualizácie a analýzy, kde nástroje ako Grafana zohrávajú kľúčovú úlohu.
- Grafana nám umožňuje vytvárať dynamické, pohľadné ovládacie panely, ktoré oživia naše údaje, čo je možné vidieť na obrázku nižšie.

Okamžité upozornenia s AlertManager
Metriky zozbierané, vizualizácie nakonfigurované – no nemôžeme neustále monitorovať Grafanu, pretože to množstvo informácií je ohromujúci.
Prichádza Alertmanager, , dôležitá súčiastka ekosystému pozorovateľnosti, navrhnutý na zjednodušenie správy upozornení.
Elegantne riadi upozornenia generované systémom Prometheus, efektívne rieši duplikáciu, zoskupovanie a trasovanie, zabezpečuje, že oznámenia sú zmysluplné a spravovateľné.
Integrácia Alertmanagera so širokou škálou platforiem oznamovania, ako napríklad:
- PagerDuty pre plánovanie hovorov
- Slack fpre tímovú komunikáciu
- Discord pre zapojenie komunity
zabezpečuje, že upozornenia dosiahnu správne osoby prostredníctvom ich preferovaných kanálov.

Pavol Krajkovic
DevOps Specialist and Consultant

